|
|
智能语音:AI时代的头十年和后十年 前十年:解决行业问题,医疗教育等,大数据和机器学习迅速提升效率与准确率; 后十年:升级到消费产品和用户生活场景(无人驾驶车,智能家居,家用机器人等领域)。 我们现在正处于语音智能产品的爆发之际,我们需要一个专业而系统的归纳,帮助我们在语音交互和智能硬件的道路上共同探索和学习。今天我们就来讨论关于语音界面设计方面的一些知识,本文章观点大部分来自入《语音用户界面设计—对话式体验设计原则》这本书,希望能够对大家有帮助。 第一:语音界面简史
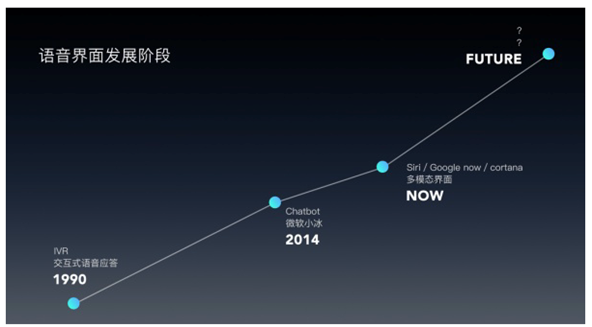
1990年出现了交互模式的语音应答,一般都广泛的应用在运营上的客服,即使是现在三大运营上的机器客服还是采用了这种语音应答的方式。通过电话拨号的方式开始语音的问答,存在很多的缺点例如只能应用在单轮任务的问答,交互方式比较单一,不能进行中途打断等缺点。
后期各大公司都出现了自己的语音助手,例如微软的cortana,谷歌的Google OK和苹果的Siri。这些语音助手集成了视觉和语音信息的app,可以同时使用语音和屏幕交互,是一种多模态界面,属于多模态设计。发展到这个阶段就有了多轮对话的可能性,如何对用户的语音进行理解就成为了语音交互的技术瓶颈了。 近两年,各大公司都出了自己的智能家居音箱,例如amzon echo和Googlehome这类的纯语音设备。在未来的生活和工作场景中语音交互是一个新的入口,它提供了更灵活的交互方式,在未来的某一天人们必然会放弃屏幕和手势的操作,可以通过语音进行远距离的设备控制,这是各大公司抢占语音市场的原因。 第二:在语音界面的设计中,vui应该注意什么?
在我个人看来,vui设计和普通的互联网的设计没有太多的不一样,如果非要说区别我个人认为vui设计所接触和涉及的范围更广。主要有下面几个工作内容:第一:进行用户研究,了解用户是谁;负责产品的原型设计和产品描述;描述系统与用户之间的交互行为并考虑需要处理的请求,最后进行系统问题的排查和改进。 Vui设计师在设计一个产品的时候,需要考虑你的产品是什么类型的,他的主要功能是什么,多模态产品还是纯语音的硬件设备。在设计过程中可以通过示例对话的方式让vui设计师真正的了解产品,知道用户在和产品对话时会发生什么样的情况。 第三:语音界面设计的常用规则有哪些? 1、命令-控制模式/对话模式 在设计语音产品之前我们需要了解一些语音识别技术,从而让你的vui系统得以创建。在系统对人的语音理解方面分为两大类:asr:自动语言理解和nlu自然语言理解,目前的发展阶段已经到了自然语言理解的阶段。机器通过处理和理解文本,采用云处理的方式对用户语音进行识别和理解从而判断指令给出正确的反馈。
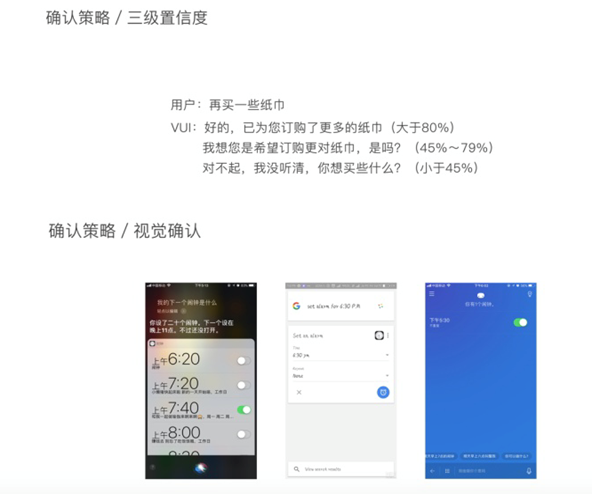
一般的vui系统在对话模式上可以分为:命令-控制模式/对话模式,语音指令模式下用户在说话前必须要给系统明确的指示。 例如:Siri要求用户在说话前必须先按下主屏幕或者在Siri页面按下麦克风图标。对话模式情况下当出现较长的对话时,没有必然让用户在说话前总是告诉系统用户要开始说话了,一般来说一个语音系统都会有命令控制模式和对话模式的切换。 在视觉的表现上两者都需要有明确的物理图标和明确的唤醒词语,在对话模式中轮流对话更为自然,在视觉上需要有明确的开始和结束的封闭式对话标示。 2、确认策略 所有优秀的vui设计,都必须确保用户感觉到自己是被理解的,所以我们需要在设计原则中添加一个确认策略。确认策略是因为在很多环境下机器并不能完全的识别我所说的问题,同时在生活场景下,例如购物等场景,需要用户的在此确认,这个时候vui的确认策略就派上用场了。在设计确认策略的过程中我们需要了解几个问题:交互问答的错误后果是什么?系统需要什么样的方式怎么反馈?屏幕需要显示出什么?用户需要用什么样的手段进行确认? 在确认的形式上可以分为:显性确认和隐性确认,例如:判断是否确认支付,这一类型的产生的后果还是挺严重的,需要强制用户确认信息 通常采用的方法有下面几种:三级置信度/隐性确认/非语言式确认/通用确认/视觉确认 多模态的设计中,屏幕上的可视化列表。比如我们的语音助手,用户说打开或者关闭语音助手,那么相应的麦克风图标会有消失和出现的动效。
答案连同原始的问题一起回复Siri通过视觉上的可视化列表和语言上的隐性确认来回复我的问题。
纯语音设备或者系统下,可以提供一个行为反馈,例如光效等
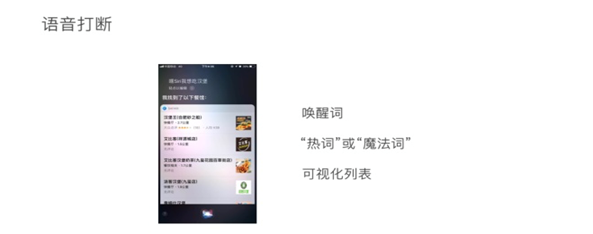
Vui系统在说话的时候,确认用户是否可以打断,现在一般的语音智能听到唤醒词才会停止说话,唤醒词应在本地处理,设备一直处于接收唤醒词的状态。多模态形式下,一般是不可以打断的,可以用可视化列表,如Siri不可以打断对话。 3、异常情况处理 在语音识别和指令的场景下异常情况极为普遍,例如:未检测到语音,语音终止超时和无语音超时;检测到语音但是没有识别出来;正确识别但是系统无法处理;部分语音识别错误等异常情况,不同的异常情况也对应不同的异常情况的处理方式,具体的方法看下图:
在这种情况下系统留给用户说话和思考的时间,某些场景下可以调整时间和灵活度。例如开始启动siri时,是用户主动的一个行为,用户不需要进行思考;然后当系统问用户某一问题时,需要用户思考,那么这个时候需要的时间就不一样了。
这个可能与语音识别技术相关联在一起了。比如说我们的语音助手,用户说打开word,系统列出:打开word/打开我的/打开卧底等等。 第四:语音的发展趋势
例如上下文语意的理解,当然我们对siri说我想吃汉堡 它列出了几个附近的餐馆用户说好腻,不吃了 这个时候就需要系统理解上下文的语境。 消除歧义:系统问用户,你的主要症状是什么,而用户说的是发烧和感冒,系统就要理解用户说的是两个症状,针对这个事情,系统需要进行回复Siri和cortana出发处理问题的时候,会提供一个网页搜索,并不会直接回答你的问题,但高级自然语言理解可以听懂你说的话,直接回答。
|